概述
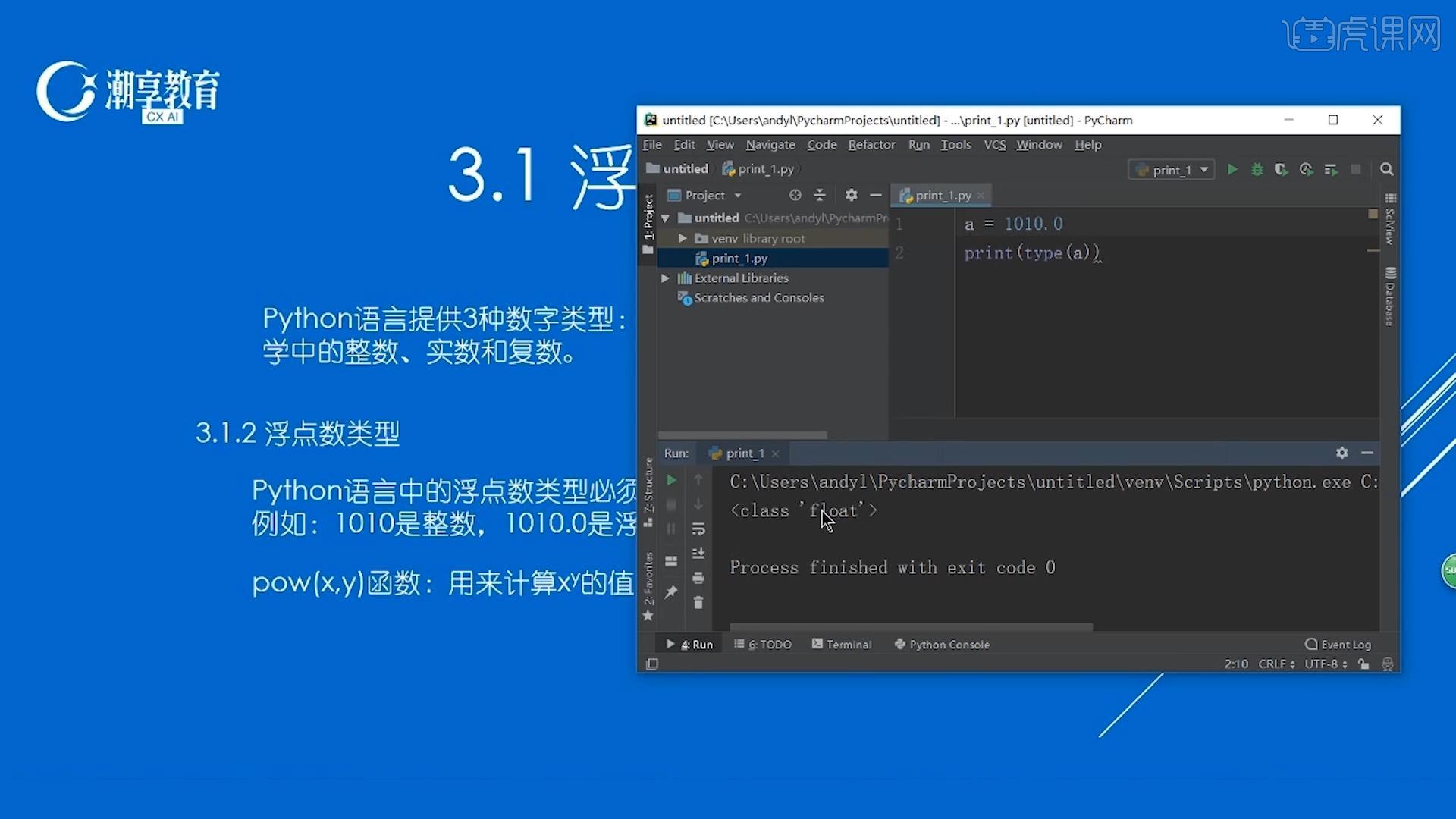
浮点数是一种计算机数据类型,用于表示实数。它们与整数不同,因为它们可以包含小数部分。浮点数通常用于表示在科学、工程和金融等领域中发现的数字。float 和 double
在 C、C++ 和 Python 等编程语言中,有两种主要的浮点数类型:float 和 double。float (float32) 是一种单精度浮点数,占用 4 个字节(32 位)。它可以表示大约 7 个有效数字(小数点后的数字)。double (float64) 是一种双精度浮点数,占用 8 个字节(64 位)。它可以表示大约 15 个有效数字。精度
float 的精度比 double 低。这意味着 float 所表示的数字的精确度较低,并且可能存在舍入误差。对于需要高精度的计算,例如科学建模,建议使用 double。范围
float 和 double 都具有有限的范围。float 的最小值为 -3.402823e+38,最大值为 3.402823e+38。double 的最小值为 -1.7976931348623157e+308,最大值为 1.7976931348623157e+308。性能
float 比 double 占用更少的内存,并且在计算中更快。但是,double 提供了更高的精度。在性能与精度之间进行权衡时,您应该根据特定的应用程序选择适当的数据类型。示例
在 Python 中,您可以使用以下语法声明浮点数:```pythonmy_float = 3.14本文原创来源:电气TV网,欢迎收藏本网址,收藏不迷路哦!





添加新评论