
在计算机编程中,主程序与子程序的交互是软件开发过程中的核心环节之一。
在许多情况下,我们需要主程序重复调用子程序实例来完成一系列的任务。
这不仅关乎代码效率,也涉及到软件性能和稳定性的考量。
那么如何通过主程序有效地重复调用子程序实例呢?以下是一些相关的技巧和策略。
一、理解主程序与子程序的关系
在主程序中,我们通常会定义一些任务或目标,然后通过调用子程序来实现这些任务。
子程序是完成特定功能的程序代码段,可以被主程序或其他子程序调用。
因此,首先需要明确主程序与子程序的职责划分,确保子程序的功能是独立、可复用且易于测试的。
二、掌握子程序的参数传递方式
为了实现主程序对子程序的灵活调用,我们需要掌握参数传递的方式。
参数传递是主程序与子程序之间数据交换的桥梁。
在调用子程序时,我们可以传递输入参数、输出参数或同时使用两者。
对于需要重复调用的子程序,确保参数传递的效率和准确性至关重要。
三、利用循环结构实现重复调用
当需要重复执行某个子程序时,我们可以使用循环结构来实现。
常见的循环结构包括for循环、while循环等。
通过设定循环条件,我们可以控制子程序的执行次数和顺序。
例如,在每次循环中调用子程序处理一组数据,直到所有数据被处理完毕。
四、采用面向对象编程的思想创建和管理子程序实例
在面向对象的编程环境中,我们可以通过创建类来封装子程序的功能和数据。
这样,我们可以创建多个类的实例来代表不同的子程序。
在主程序中,我们可以通过实例化类来创建子程序的实例,并重复调用这些实例来完成任务。
这种方式有助于提高代码的可读性和可维护性。
五、优化性能:避免不必要的重复调用和内存占用
在重复调用子程序时,需要注意性能优化的问题。
避免不必要的重复调用和内存占用是提高软件性能的关键。
我们可以通过以下策略来优化性能:
1. 缓存常用数据:对于在多次调用中保持不变的数据,可以将其缓存起来,避免每次调用都重新计算或获取。
2. 减少全局变量的使用:过度使用全局变量可能导致代码难以维护和理解,也可能会影响性能。尽量将变量作用域限定在函数或方法内。
3. 优化算法和数据结构:选择合适的算法和数据结构可以提高子程序的运行效率,从而优化整个程序的性能。
六、异常处理与错误日志记录
在重复调用子程序的过程中,可能会遇到一些异常情况或错误。
为了保障程序的稳定性和可靠性,我们需要进行异常处理和错误日志记录。
通过捕获异常并采取相应的处理措施,我们可以避免程序崩溃或数据丢失等问题。
同时,记录错误日志有助于我们分析和定位问题,提高软件的维护效率。
七、总结与最佳实践建议
通过以上的技巧和策略,我们可以实现主程序对子程序实例的重复调用。在实际开发中,建议遵循以下最佳实践:
1. 清晰定义主程序和子程序的职责划分。
2. 掌握参数传递的方式和技巧。
3. 使用循环结构实现重复调用。
4. 采用面向对象编程的思想创建和管理子程序实例。
5. 关注性能优化问题,避免不必要的重复调用和内存占用。
6. 进行异常处理和错误日志记录,保障程序的稳定性和可靠性。
掌握如何通过主程序重复调用子程序实例的技巧和策略对于提高软件开发的效率和质量至关重要。
通过以上最佳实践和建议,我们可以更好地实现主程序和子程序的交互,提高软件的性能和稳定性。
什么是系统进程 进程是指在系统中正在运行的一个应用程序;线程是系统分配处理器时间资源的基本单元,或者说进程之内独立执行的一个单元。 对于操作系统而言,其调度单元是线程。 一个进程至少包括一个线程,通常将该线程称为主线程。 一个进程从主线程的执行开始进而创建一个或多个附加线程,就是所谓基于多线程的多任务。 那进程与线程的区别到底是什么?进程是执行程序的实例。 例如,当你运行记事本程序(Nodepad)时,你就创建了一个用来容纳组成 的代码及其所需调用动态链接库的进程。 每个进程均运行在其专用且受保护的地址空间内。 因此,如果你同时运行记事本的两个拷贝,该程序正在使用的数据在各自实例中是彼此独立的。 在记事本的一个拷贝中将无法看到该程序的第二个实例打开的数据。 以沙箱为例进行阐述。 一个进程就好比一个沙箱。 线程就如同沙箱中的孩子们。 孩子们在沙箱子中跑来跑去,并且可能将沙子攘到别的孩子眼中,他们会互相踢打或撕咬。 但是,这些沙箱略有不同之处就在于每个沙箱完全由墙壁和顶棚封闭起来,无论箱中的孩子如何狠命地攘沙,他们也不会影响到其它沙箱中的其他孩子。 因此,每个进程就象一个被保护起来的沙箱。 未经许可,无人可以进出。 实际上线程运行而进程不运行。 两个进程彼此获得专用数据或内存的唯一途径就是通过协议来共享内存块。 这是一种协作策略。 下面让我们分析一下任务管理器里的进程选项卡。 这里的进程是指一系列进程,这些进程是由它们所运行的可执行程序实例来识别的,这就是进程选项卡中的第一列给出了映射名称的原因。 请注意,这里并没有进程名称列。 进程并不拥有独立于其所归属实例的映射名称。 换言之,如果你运行5个记事本拷贝,你将会看到5个称为的进程。 它们是如何彼此区别的呢?其中一种方式是通过它们的进程ID,因为每个进程都拥有其独一无二的编码。 该进程ID由Windows NT或Windows 2000生成,并可以循环使用。 因此,进程ID将不会越编越大,它们能够得到循环利用。 第三列是被进程中的线程所占用的CPU时间百分比。 它不是CPU的编号,而是被进程占用的CPU时间百分比。 此时我的系统基本上是空闲的。 尽管系统看上去每一秒左右都只使用一小部分CPU时间,但该系统空闲进程仍旧耗用了大约99%的CPU时间。 第四列,CPU时间,是CPU被进程中的线程累计占用的小时、分钟及秒数。 请注意,我对进程中的线程使用占用一词。 这并不一定意味着那就是进程已耗用的CPU时间总和,因为,如我们一会儿将看到的,NT计时的方式是,当特定的时钟间隔激发时,无论谁恰巧处于当前的线程中,它都将计算到CPU周期之内。 通常情况下,在大多数NT系统中,时钟以10毫秒的间隔运行。 每10毫秒NT的心脏就跳动一下。 有一些驱动程序代码片段运行并显示谁是当前的线程。 让我们将CPU时间的最后10毫秒记在它的帐上。 因此,如果一个线程开始运行,并在持续运行8毫秒后完成,接着,第二个线程开始运行并持续了2毫秒,这时,时钟激发,请猜一猜这整整10毫秒的时钟周期到底记在了哪个线程的帐上?答案是第二个线程。 因此,NT中存在一些固有的不准确性,而NT恰是以这种方式进行计时,实际情况也如是,大多数32位操作系统中都存在一个基于间隔的计时机制。 请记住这一点,因为,有时当你观察线程所耗用的CPU总和时,会出现尽管该线程或许看上去已运行过数十万次,但其CPU时间占用量却可能是零或非常短暂的现象,那么,上述解释便是原因所在。 上述也就是我们在任务管理器的进程选项卡中所能看到的基本信息列。 什么是线程? 究竟什么是线程呢?正如在图A中所示,一个线程是给定的指令的序列 (你所编写的代码),一个栈(在给定的方法中定义的变量),以及一些共享数据(类一级的变量)。 线程也可以从全局类中访问静态数据。 栈以及可能的一些共享数据 每个线程有其自己的堆栈和程序计数器(PC)。 你可以把程序计数器(PC)设想为用于跟踪线程正在执行的指令,而堆栈用于跟踪线程的上下文,上下文是当线程执行到某处时,当前的局部变量的值。 虽然你可以编写出在线程之间传送数据的子程序,在正常情况下,一个线程不能访问另外一个线程的栈变量。 一个线程必须处于如下四种可能的状态之一,这四种状态为: 初始态:一个线程调用了new方法之后,并在调用start方法之前的所处状态。 在初始态中,可以调用start和stop方法。 Runnable:一旦线程调用了start 方法,线程就转到Runnable 状态,注意,如果线程处于Runnable状态,它也有可能不在运行,这是因为还有优先级和调度问题。 阻塞/ NonRunnable:线程处于阻塞/NonRunnable状态,这是由两种可能性造成的:要么是因挂起而暂停的,要么是由于某些原因而阻塞的,例如包括等待IO请求的完成。 退出:线程转到退出状态,这有两种可能性,要么是run方法执行结束,要么是调用了stop方法。 最后一个概念就是线程的优先级,线程可以设定优先级,高优先级的线程可以安排在低优先级线程之前完成。 一个应用程序可以通过使用线程中的方法setPriority(int),来设置线程的优先级大小。
本文原创来源:电气TV网,欢迎收藏本网址,收藏不迷路哦!
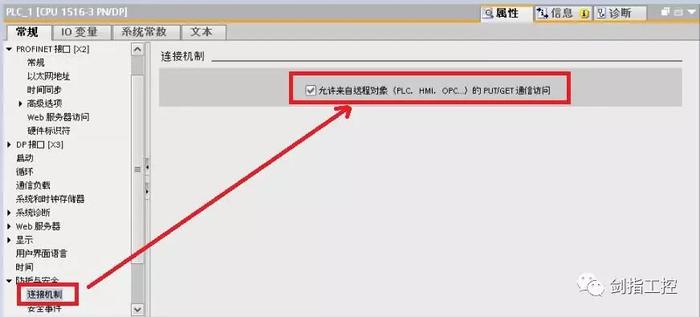

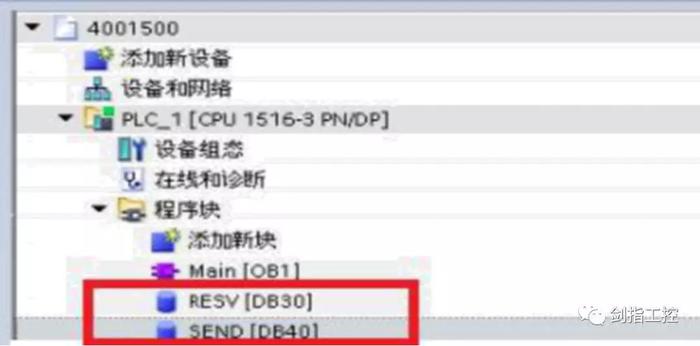




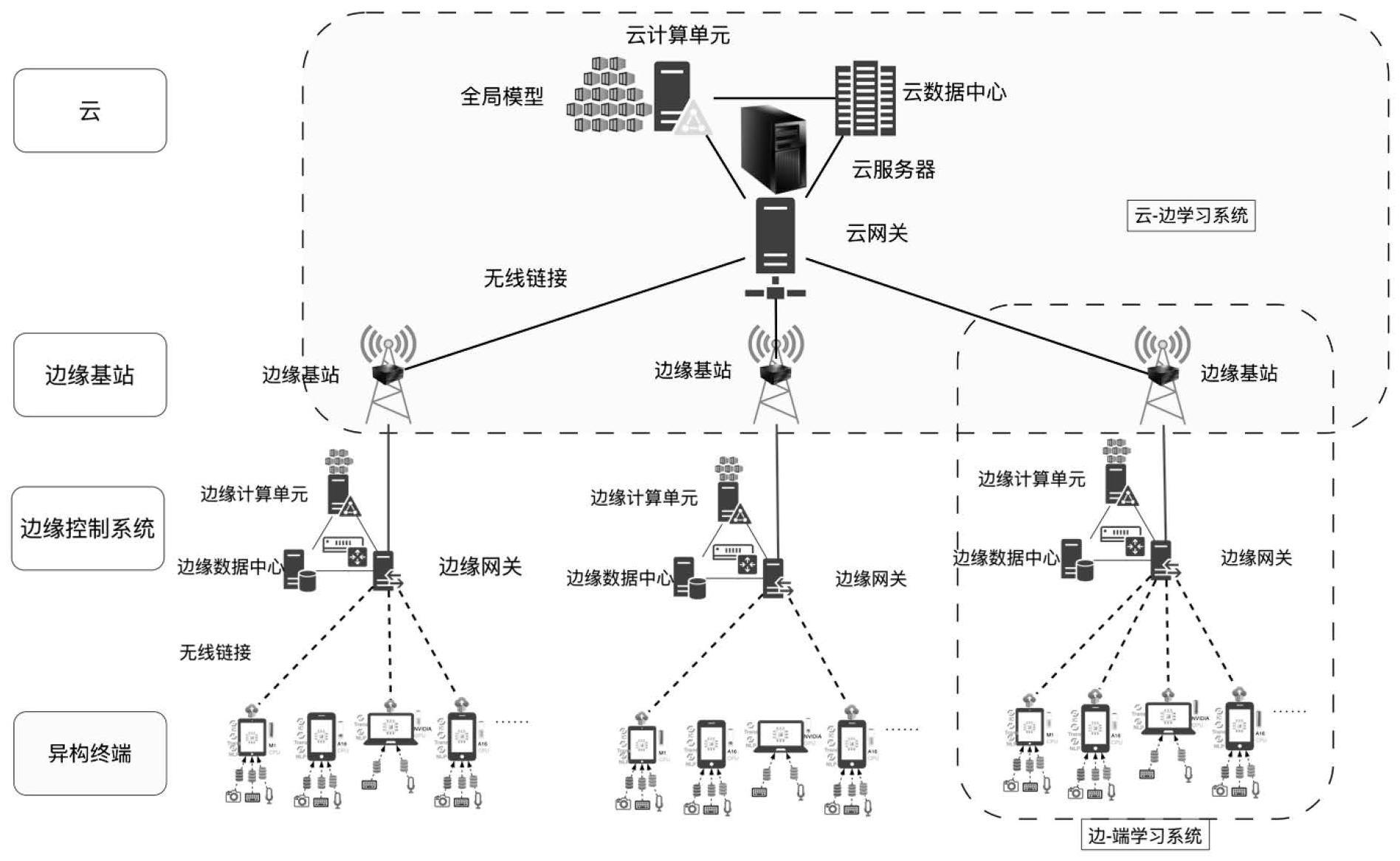
添加新评论