
一、引言
在软件开发过程中,提高代码运行效率是每个开发者追求的目标。
高效代码不仅能提高程序运行速度,还能减少资源消耗,提高用户体验。
本文将介绍一些实现高效代码运行的关键技巧,帮助开发者优化代码性能。
二、选择适当的数据结构和算法
1. 数据结构:选择合适的数据结构对于提高代码效率至关重要。不同的数据结构具有不同的时间复杂度和空间复杂度,根据实际需求选择合适的数据结构可以显著提高代码性能。例如,对于频繁查找操作,使用哈希表或二叉搜索树可以提高查找速度;对于需要频繁插入和删除操作的场景,链表可能更为合适。
2. 算法:算法的选择直接影响代码的运行效率。在选择算法时,应考虑其时间复杂度和空间复杂度,以及在实际场景中的表现。针对具体问题,可以采用动态规划、分治策略、贪心算法等优化手段,提高算法效率。
三、避免不必要的计算
在编程过程中,应尽量避免不必要的计算。
有些计算过程可能非常耗时,如果能够避免或减少这些计算,将显著提高代码运行效率。
例如,可以通过缓存计算结果、使用预计算表等方式减少重复计算。
还可以通过分析算法的时间复杂度,优化关键部分的代码,减少计算量。
四、优化内存使用
内存使用也是影响代码运行效率的重要因素。
优化内存使用可以有效提高程序的运行速度。
以下是一些优化内存使用的技巧:
1. 避免创建过多的对象:频繁创建和销毁对象会消耗大量内存和计算资源。可以通过复用对象、使用对象池等技术减少对象创建和销毁的开销。
2. 使用合适的数据类型:选择合适的数据类型可以减少内存占用。例如,使用整数类型代替字符串类型可以节省内存空间。
3. 避免过度使用全局变量:过度使用全局变量可能导致内存泄漏和性能问题。应尽量使用局部变量和对象属性来存储数据。
五、利用并发和多线程技术
并发和多线程技术是提高代码运行效率的重要手段。
通过并发和多线程技术,可以将任务分配给多个线程并行执行,提高程序的运行速度和响应能力。
以下是一些利用并发和多线程技术的技巧:
1. 使用异步编程:异步编程可以充分利用系统资源,提高程序的并发性能。通过异步IO、异步任务等技术,可以避免阻塞等待IO操作完成,提高程序的响应速度。
2. 合理分配线程资源:在创建多线程时,应根据任务类型和系统资源合理分配线程数量。过多的线程可能导致上下文切换频繁,影响性能;过少的线程则可能无法充分利用系统资源。
3. 使用锁和同步机制:在多线程环境下,应使用锁和同步机制确保数据的安全性和一致性。合理设计锁粒度,避免死锁和活锁等问题。
六、代码优化与重构
代码优化和重构是提高代码运行效率的重要环节。
通过不断地优化和重构代码,可以提高程序的可读性、可维护性和性能。
以下是一些代码优化与重构的技巧:
1. 代码重构:定期进行代码重构,将复杂的函数或类拆分为多个简单模块,提高代码的可读性和可维护性。
2. 使用分析工具:利用代码分析工具找出性能瓶颈和潜在问题,针对问题进行优化。
3. 测试与验证:在代码优化过程中,应进行充分的测试与验证,确保优化后的代码不引入新的问题。
七、总结
实现高效代码运行的关键技巧包括选择合适的数据结构和算法、避免不必要的计算、优化内存使用、利用并发和多线程技术以及代码优化与重构等。
在实际开发中,应根据项目需求和实际情况选择合适的技术和策略,不断优化和提高代码性能。
同时,还应注意保持良好的编程习惯和代码风格,提高代码的可读性和可维护性。
如何编写高质量的代码!
载选<编程思想>非程序员 编 著代码永远会有BUG,在这方面没有最好只有更好。高效是程序员必须作到的事情,无错是程序员一生的追求。复用、分而治之、折衷是代码哲学的基本思想。模块化与面向对象是实现高效无错代码的方法。高效无错代码需要思想与实践的不断反复。1.2.1 命名约定命令规范基本上采用了微软推荐的匈牙利命名法,略有简化。1. 常量常量由大写字母和数字组成,中间可以下划线分隔,如 CPU_8051。2. 变量变量由小写(变量类型)字母开头,中间以大写字母分隔,可以添加变量域前缀(变量活动域前缀以下划线分隔)。如: v_nAcVolMin(交流电压最小值)。变量域前缀见下表局部变量,如果变量名的含义十分明显,则不加前缀,避免烦琐。如用于循环的int型变量 i,j,k ;float 型的三维坐标(x,y,z)等。3. 函数名一般由大写字母开头,中间以大写字母分隔,如SetSystemPara。函数命名采用动宾形式。如果函数为最底层,可以考虑用全部小写,单词间采用带下划线的形式。如底层图形函数:pixel、lineto以及读键盘函数get_key 等。4. 符号名应该通用或者有具体含义,可读性强。尤其是全局变量,静态变量含义必须清晰。C++中的一些关键词不能作为符号名使用,如class、new、friend等。符号名长度小于31个,与ANSI C 保持一致。命名只能用26个字母,10个数字,以及下划线‘_’来组成,不要使用‘$’‘@’等符号。下划线‘_’使用应该醒目,不能出现在符号的头尾,只能出现在符号中间,且不要连续出现两个。5. 程序中少出现无意义的数字,常量尽量用宏替代。1.2.2 使用断言程序一般分为Debug版本和Release版本,Debug版本用于内部调试,Release版本发行给用户使用。断言assert是仅在Debug版本起作用的宏,它用于检查“不应该”发生的情况。以下是一个内存复制程序,在运行过程中,如果assert的参数为假,那么程序就会中止(一般地还会出现提示对话,说明在什么地方引发了assert)。 //复制不重叠的内存块 void memcpy(void *pvTo, void *pvFrom, size_t size){ void *pbTo = (byte *) pvTo; void *pbFrom = (byte *) pvFrom; assert( pvTo != NULL && pvFrom != NULL ); while(size - - > 0 ) *pbTo + + = *pbFrom + + ; return (pvTo);}assert不是一个仓促拼凑起来的宏,为了不在程序的Debug版本和Release版本引起差别,assert不应该产生任何副作用。所以assert不是函数,而是宏。程序员可以把assert看成一个在任何系统状态下都可以安全使用的无害测试手段。以下是使用断言的几个原则:1)使用断言捕捉不应该发生的非法情况。不要混淆非法情况与错误情况之间的区别,后者是必然存在的并且是一定要作出处理的。2)使用断言对函数的参数进行确认。3)在编写函数时,要进行反复的考查,并且自问:“我打算做哪些假定?”一旦确定了的假定,就要使用断言对假定进行检查。4)一般教科书都鼓励程序员们进行防错性的程序设计,但要记住这种编程风格会隐瞒错误。当进行防错性编程时,如果“不可能发生”的事情的确发生了,则要使用断言进行报警。1.2.3 优化/效率规则一:对于在中断函数/线程和外部函数中均使用的全局变量应用volatile定义。例如:volatile int ticks;void timer(void) interrupt 1 //中断处理函数{ ticks++}void wait(int interval){ tick=0; while(tick 例如:="bool=" c++没有理由对c存在傲慢与偏见,不是任何场合c++方法都是解决问题的良药,譬如面对嵌入式系统效率和空间的双重需求。 注意我们谈的是方法,而不是指编译器。 ="c在软件开发上存在的首要问题是缺乏对数据存取的控制(封装),c编程者乐而不疲的使用着大量extern形式的全局变量在各模块间交换着数据,“多方便啊”编程者乐曰,并传授给下一个编程者。 这样多个变量出现在多个模块中,剪不断理还乱,直到有一天终于发现找一个“人”好难。 一个东西好吃,智者浅尝之改进之,而愚者只会直至撑死。 =" do="something=" flag;="…=" getonestruct(void);="获取模块1数据接口=" if(flag)="{=" m¬_imember;="……=" onestruct="int=" onestruct*="void=" pt1="&t1;" pt1;="只需定义一个局部变量=" return="ponestruct)=" setonestruct(onestruct*="ponestruct);=" t1初始化代码…..="getonestruct(void)=" }="如果未用volatile,由于while循环是一个空循环,编译器优化后(编译器并不知道此变量在中断中使用)将会把循环优化为空操作!这就显然不对了。 =" }t1;="模块1的数据=" 不合理的用法="规则三:小心不要将“==”写成“=”,编译器不会自动发现这种错误。 " 以下展示了两个c模块交换数据:="module1.c=" 传指针参数增加的开销主要是作参数的指针和局部指针的数据空间(嵌入式系统(如c51)往往由于堆栈空间有限,函数参数会放到外部ram的堆栈中),增加的代码开销仅是函数的调用,带来的是良好的模块化结构,而且使用接口函数会比在代码中多处直接使用全局变量大大节约代码空间。 ="需注意一点的事物总有他的两面性,水能载舟,也能覆舟。 对于需要频繁访问的变量如果仍采用接口传递,函数调用的开销是巨大的,这时应考虑仍采用extern全局变量。 =" 其他="规则一:不要编写集多种功能于一身的函数,在函数的返回值中,不要将正常值和错误标志混在一起。 =" 写模块1数据接口="struct=" 危险的用法="if(!flag)=" 最后需要明确一点的是这里的模块是以一个.c文件为单位。 ="规则一:利用函数命名规则和静态函数=" 模块中不能被其他模块读写的全局变量应采用static声明,这样在其他模块错误地读写这些变量时编译器能给出警告(c51编译器)或错误(bc编译器)。 ="规则三:引入oo接口概念和指针传参=" 模块中不被其他模块调用的内部函数采用以下命名规则:用全部小写,单词间采用带下划线的形式。 如底层图形函数:pixel、lineto以及读键盘函数get_key等。 这些函数应定义为static静态函数,这样在其他模块错误地调用这些函数时编译器能给出错误(如bc编译器)。 (注意:有些编译器不能报告错误,但为了代码风格一致和函数层次清晰,仍建议这样作)。 ="规则二:利用静态变量=" 模块化的c编程="c语言虽然不具备c++的面向对象的成分,但仍应该吸收面向对象的思想,采用模块化编程思路。 面向对象的思想与面向对象的语言是两个概念。 非面向对象的语言依然可以完成面向对象的编程,想想c++的诞生吧!=" 模块间的数据接口(也就是函数)应该事先较充分考虑,需要哪些接口,通过接口需要操作哪些数据,尽量作到接口的不变性。 ="模块间地数据交换尽量通过接口完成,方法是通过函数传参数,为了保证程序高效和减少堆栈空间,传大量参数(如结构)应采用传址的方式,通过指针作为函数参数或函数返回指针,尽量杜绝extern形式的全局变量,请注意是extern形式的全局变量,模块内部的全局变量是允许和必须的。 =" 正确的用法="if(flag==TRUE)" 规则三:变量类型编程中应用原则:尽量采用小的类型(如果能够不用“float”就尽量不要去用)以及无符号unsigned类型,因为符号运算耗费时间较长;同时函数返回值也尽量采用unsigned类型,由此带来另外一个好处:避免不同类型数据比较运算带来的隐性错误。 ="1.2.4=" 规则二:不要将bool值true和false对应于1和0进行编程。 大多数编程语言将false定义为0,任何非0值都是true。 visual="c++将true定义为1,而visual=" 规则二:不要编写一条过分复杂的语句,紧凑的c++="c代码并不见到能得到高效率的机器代码,却会降低程序的可理解性,程序出错误的几率也会提高。 =" 规则四:建议统一函数返回值为无符号整形,0代表无错误,其他代表错误类型。 ="1.3=" 这世上本没有什么救世主,应在c上多下功夫,程序员和c缔造者早就有过思考,相信野百合也有春天,还是看看c语言如何实现模块化编程方法,在部分程度上具备了oo特性封装与多态。 ="在具体阐述之前,需要明确生存期与可见性的概念。 生存期指的是变量在内存的生存周期,可见性指的是变量在当前位置是否可用。 两者有紧密联系,但不能混为一谈。 一个人存在但不可见只能解释成上帝或灵魂,一个变量存在但不可见却并非咄咄怪事,模块化方法正是利用了静态函数、静态变量这些“精灵”们特殊的生存期与可见性。 ="> imember; //…….}// OperateOneStruct(void); //模块2通过模块1提供的接口操作模块1的数据OneStruct* void GetOneStruct(void);void SetOneStruct(OneStruct* pOneStruct);void OperateOneStruct(void){ OneStruct* pt2; //只需定义一个局部变量 pt2=GetOneStruct(); //读取数据 SetOneStruct(pt2); //改写数据}采用接口访问数据可以避免一些错误,因为函数返回值只能作右值,全局变量则不然。 例如 cOneChar == 4; 可能被误为cOneChar = 4;规则四:有限的封装与多态不要忘记C++的class源于C的struct,C++的虚函数机制实质是函数指针。 为了使数据、方法能够封装在一起,提高代码的重用度,如对于一些与硬件相关的数据结构,建议采用在数据结构中将访问该数据结构的函数定义为结构内部的函数指针。 这样当硬件变化,需要重写访问该硬件的函数,只要将重写的函数地址赋给该函数指针,高层代码由于使用的是函数指针,所以完全不用动,实现代码重用。 而且该函数指针可以通过传参数或全局变量的方式传给高层代码,比较方便。 例如:struct OneStruct{int m¬_imember;int (*func)(int,int);//……}t2;
[探讨]提高代码质量的方法有哪些?
人跟人的能力千差万别,所以写出来的代码质量,肯定是不同的。 有的人,写一个小逻辑,可能需要100行,而有的人,可能仅仅需要10行。 代码永远会有Bug,在这方面没有最好只有更好。 高效是程序员必须作到的事情,无错是程序员一生的追求。 复用、分而治之、折衷是代码哲学的基本思想。 模块化与面向对象是实现高效无错代码的方法。 高效无错代码需要思想与实践的不断反复。 如何做到代码高效无错,提高代码质量的方法有哪些?又有哪些经验和技巧呢?本文整理自知乎网,与开发者们一起探讨该话题。 如果您有好的想法,欢迎在评论中列出。 一起来看下编程界各位大牛如何为您支招:互联网评论员 孙立伟:1. 代码风格和规范多看看网上的一些代码规范,仔细思考一下制定这些规范的出发点是什么。 例如Oracle(前SUN)公司的代码规范,Google的代码规范googlecode。 2. 学习最佳实践在编码中遇到的各种大大小小的问题,首先不是自己去“闭门造车”的冥思苦想,多用Google,搜搜是否已经有现成的解决方案。 3. 阅读优秀的开源代码网上有很多优秀的开源项目,针对你自己项目中遇到的问题,找找类似的开源项目,学习、研究,最重要的是变成自己的东西。 4. 学好英语英语是目前所有编程语言的基础。 你的文件名、类名、方法名、变量名都是需要一个好的英语基础才能够起得合适。 任何的业务逻辑,都需要你使用以英语为基础的计算机语言表达出来。 英语不好,你的代码永远看起来不专业。 互联网评论员 钟声:靠牛人带,靠代码Review,应该对初期成长很有帮助,不过受环境限制较大,可能并不是所有人都能有这种幸运。 多看启发思路的书,多看开源代码,用辅助工具(lint、findbugs等),都是靠谱的答案,不过我还想补充一点,在这些标准答案背后,更重要的一点:要充分利用自己的敏感,当看着一堆需要自己负责的成品、半成品代码时,哪怕只有一点点的不爽,千万不要忍,而要勇敢地——改!大刀阔斧、大张旗鼓!其实道理并不复杂:重复的东西可以合并,零散的逻辑可以集中。 让一切保持有条不紊,只需要拆解得当。 此时,那些曾经空洞的理论开始具现化,节省了思考的时间,也成为了顺手的工具。 “DRY”一个词就可以说明白原则,“技术债务”一个词就可以争取到重构时间。 DSP软件程序员 冯旭辉:1.学会模块分割是提高代码质量的关键人的精力有限,人的经验也有限,但把问题拆分成子问题,形成一个个独立的模块,这就可以让我们的精力更加集中于某个细微的问题,无论如何,都会大大提高模块的编写质量。 2.要从一开始就养成一个良好的编码风格比如函数的头部注释的格式,函数间的分割方式,函数组的分割方式形成固定的程式。 并使用编辑器的宏功能预先做好快捷方式,需要时直接生成出来这些格式化文本。 3.需要使用CVS之类的源代码版本管理工具每完成一个小功能改进或者bug修复就提交,这样下来,你的工作就是逐步精化。 4.使用诸如MantisBT之类的bug管理工具对每一个出现的bug,修改完成后,进行详细的处理过程描述,以备今后再犯类似的错误。 还有些码农认为,应该多读好的代码,比如著名开源框架的代码的写法,在保证功能、效率的基础上思考结构,回顾下自己编写的代码;反复评审代码,规范代码、改进实现方案的写法。 同时还应该尽一切努力减少代码重复,将代码分解为自成体系,可测试的小块 ;最后测试,测试,再测试。 当然这还需要有很强的毅力。 以上这些观点,您赞同吗?
如何提高代码执行效率?
尽量使用局部变量,少定义静态变量或方法,尽量重用变量,减少线程,减少循环嵌套
本文原创来源:电气TV网,欢迎收藏本网址,收藏不迷路哦!
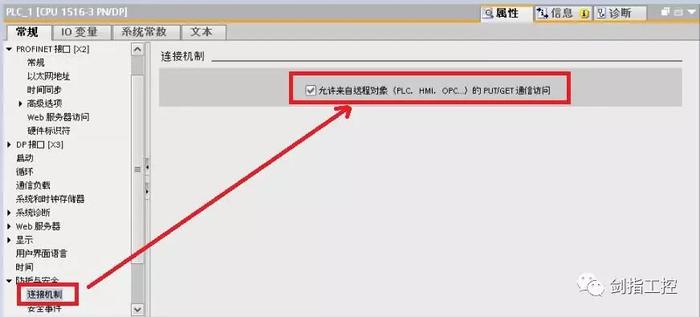

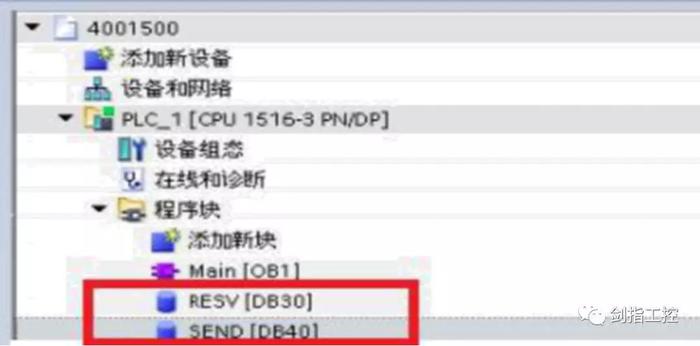




添加新评论